What is Apache?
In short, Apache is the most popular web server available. Its basic job is to accept requests from clients and send responses to those requests. A web server receives a URL, translates it to a filename, that's for static requests, and sends that file back over the Internet from the local disk. It can also translate it to a program name, that's for dynamic requests, executes it, and then sends that program output back over the Internet to the requesting party. In cases when the web server was not able to process and complete the request, it returns an error message instead. In fact, the word "web server" can refer to both the machine (computer, hardware) itself and the software that receives requests and sends out responses.

Why is Apache the most popular web server?
- It is totally free to download and install.
- It is open source. Apache source code is visible to everyone. This enables anyone who has enough technical skills to adjust the code, optimize it, and fix errors and security pitfalls. Actually, people can add new features and write new modules.
- It fits all needs. Apache can be used for small one-two page websites as well as huge resources including hundreds and even thousands of pages, and serving millions of visitors every month. It can also serve both static and dynamic content.
How Apache Works
The main role of Apache is all about communication over networks. It uses the TCP/IP protocol. It is a Transmission Control Protocol/Internet Protocol allowing devices with IP addresses within the same network communicate with one another.
The Apache server is set up to run through configuration files. Directives are added there to control its behavior. In the idle state, Apache listens to the IP addresses identified in its config file (HTTPd.conf). When it receives a request, it analyzes the headers, applies the rules specified for it in the Config file, and takes action.
As you know, one server can host many websites. However, they seem separate from one another to the outside world. How to achieve this? Every one of those websites has to be assigned a different name, even if those all map to one and the same machine. This is accomplished by using what we know as virtual hosts.
IP addresses are difficult to remember, aren't they? The visitors to specific sites usually type in their respective domain names into the URL address box on their browsers. Then, the browser connects to a DNS server, which translates the domain names to their IP addresses. Then, the browser takes the returned IP address and connects to it. Additionally, the browser sends a Host header with the request so that, if the server is hosting multiple sites, it will know which one to serve back.
For instance, typing in www.google.com into your browser's address field might send the following request to the server at that IP address:

Here's what information the first line contains. There is the method, it's a GET, in this case, the URI that specifies which page to be retrieved or which program to be run, it's the root directory denoted by the / in this case, and finally, there is the HTTP version, which is HTTP 1.1 in this case.
What is HTTP? It is a request/response stateless protocol. It's a set of rules that stipulate communication between a client and the server. The client, it's usually but not necessarily a web browser, makes a request. The server sends back a response and communication stops. The server doesn't wait for more communication as there is the case with other protocols that stay in a waiting state after the request is over.
When the request is successful, the server returns a 200 status code (this means that the page is found), response headers, along with the requested data. The response header of an Apache server might look something like this:
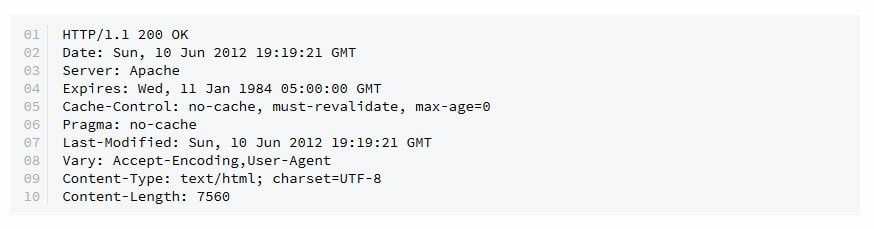
So, the first line in the response header is the status line. It consists of the HTTP version and the status code. Next goes the date, and then bits of information about the host server and the retrieved data. The Content-Type header allows the client know the type of data retrieved so it knows how to handle it. Content-Length makes the client know the size of the response body. What happens if the request didn't go throw? The client would get an error code and message, such as the following response header in case of the page not found error:

Related terms: BSA | The Software Alliance - an advocate for public policies fostering technology innovation and driving economic growth, Java Platform, Enterprise Edition (Java EE) - a collection of Java APIs that can be used by software developers for writing server-side applications, microservices - this is an approach to application development where large application is built as a suite of modular services.
References and further reading:
- Apache HTTP Server - Wikipedia.
- The Apache Software Foundation - an American non-profit corporation resource to support Apache software projects that include the Apache HTTP Server.
- The Apache HTTP Server Project - it efforts to develop and maintain an open-source HTTP server for modern operating systems that include UNIX and Windows.
- Apache Usage Statistics.
- Newest 'apache' Questions - Stack Overflow.
- Apache Tutorials | DigitalOcean.